Anthropic’s AI Fluency Index Establishes Baseline for Human‑AI Collaboration
Published Cached
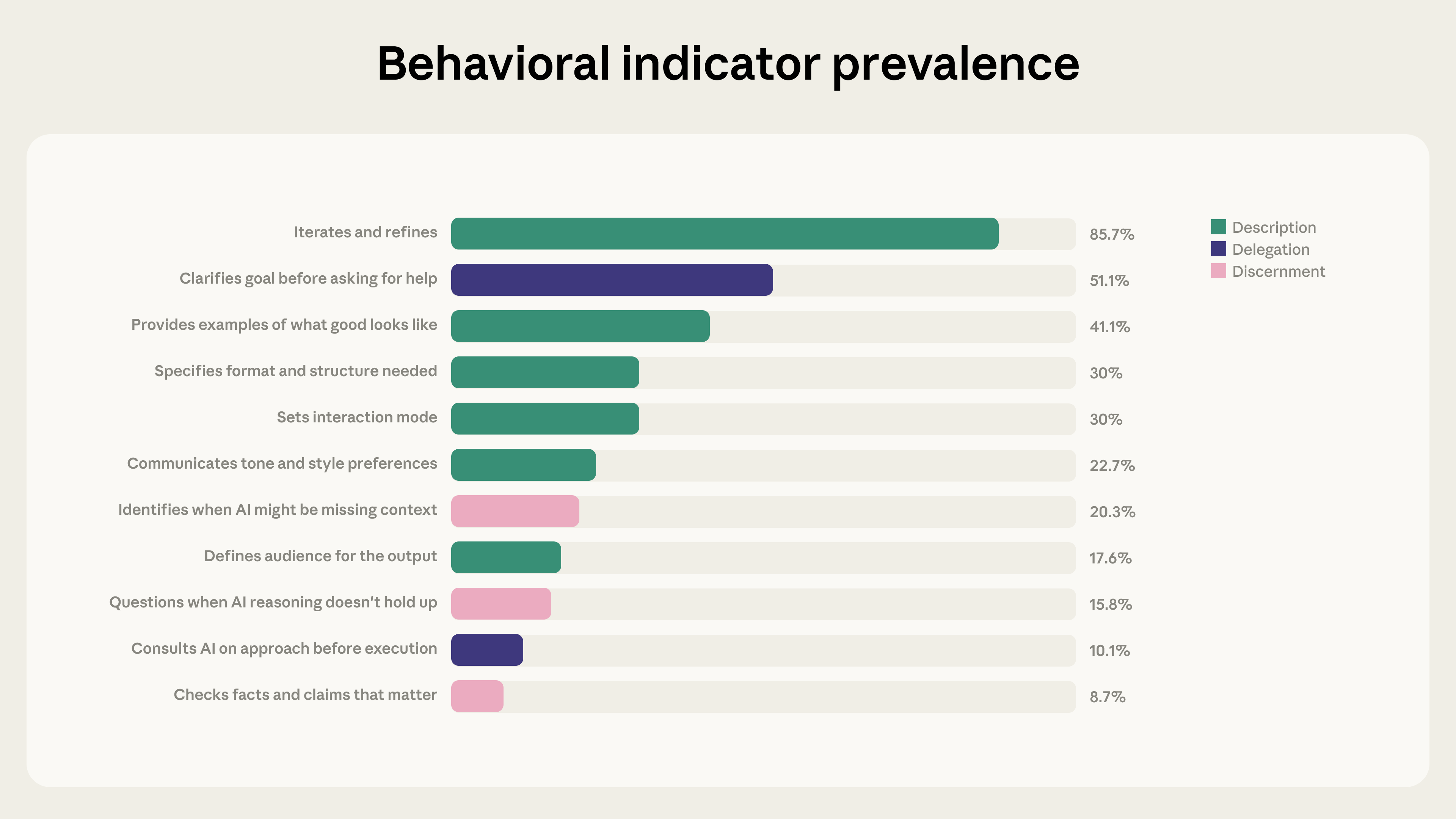
Anthropic publishes baseline AI Fluency Index from Claude.ai chats The report analyzes 9,830 multi‑turn conversations on Claude.ai during a seven‑day window in January 2026, measuring 11 observable behaviors drawn from the 24‑behavior 4D AI Fluency Framework [1][6].
Iteration and refinement markedly increase fluency behaviors 85.7 % of the sampled conversations involve users building on prior exchanges; these dialogs show on average 2.67 additional fluency behaviors versus 1.33 in non‑iterative chats, and users are 5.6 × more likely to question Claude’s reasoning and 4 × more likely to spot missing context [1].
Artifact‑producing conversations are more directive but less evaluative 12.3 % of chats generate code, documents, or interactive tools; users in these sessions more often clarify goals (+14.7 pp), specify formats (+14.5 pp), give examples (+13.4 pp) and iterate (+9.7 pp), yet they are less likely to identify missing context (‑5.2 pp), check facts (‑3.7 pp), or ask Claude to explain its reasoning (‑3.1 pp) [1].
Treating AI as a thought partner is the dominant fluency pattern Across the dataset, augmentative use—where users view Claude as a collaborator rather than a delegator—appears most frequently, with conversations exhibiting more than double the number of fluency behaviors compared with brief back‑and‑forth exchanges [1][4].
Findings are limited to early‑adopter Claude.ai users and observable behaviors The sample reflects a single week of activity from users comfortable with AI, excludes seasonal effects, and captures only 11 of the 24 framework behaviors; unobservable ethical and responsible‑use dimensions remain unmeasured [1].
Anthropic plans broader cohort and qualitative studies to track fluency evolution Future work will compare new versus experienced users, apply qualitative methods to assess hidden behaviors, test causal impacts of iterative prompting, and extend analysis to Claude Code, which serves a developer audience [1].
Links
- [1] https://www.anthropic.com/research/AI-fluency-index
- [10] http://claude.ai/redirect/website.v1.b23a11d4-c9ba-434c-83eb-082f855a0d87
- [11] http://claude.ai/redirect/website.v1.b23a11d4-c9ba-434c-83eb-082f855a0d87
- [2] https://www.anthropic.com/news/anthropic-education-report-how-university-students-use-claude
- [3] https://www.anthropic.com/news/anthropic-education-report-how-educators-use-claude
- [4] https://www.anthropic.com/research/economic-index-primitives
- [5] https://www.anthropic.com/research/AI-assistance-coding-skills
- [6] https://anthropic.skilljar.com/ai-fluency-framework-foundations
- [7] https://www.anthropic.com/research/clio
- [8] https://claude.ai/redirect/website.v1.b23a11d4-c9ba-434c-83eb-082f855a0d87/catalog/artifacts
- [9] https://www.anthropic.com/research/anthropic-economic-index-january-2026-report