Claude Code autonomy rises as users gain experience, study finds
Published Cached
-
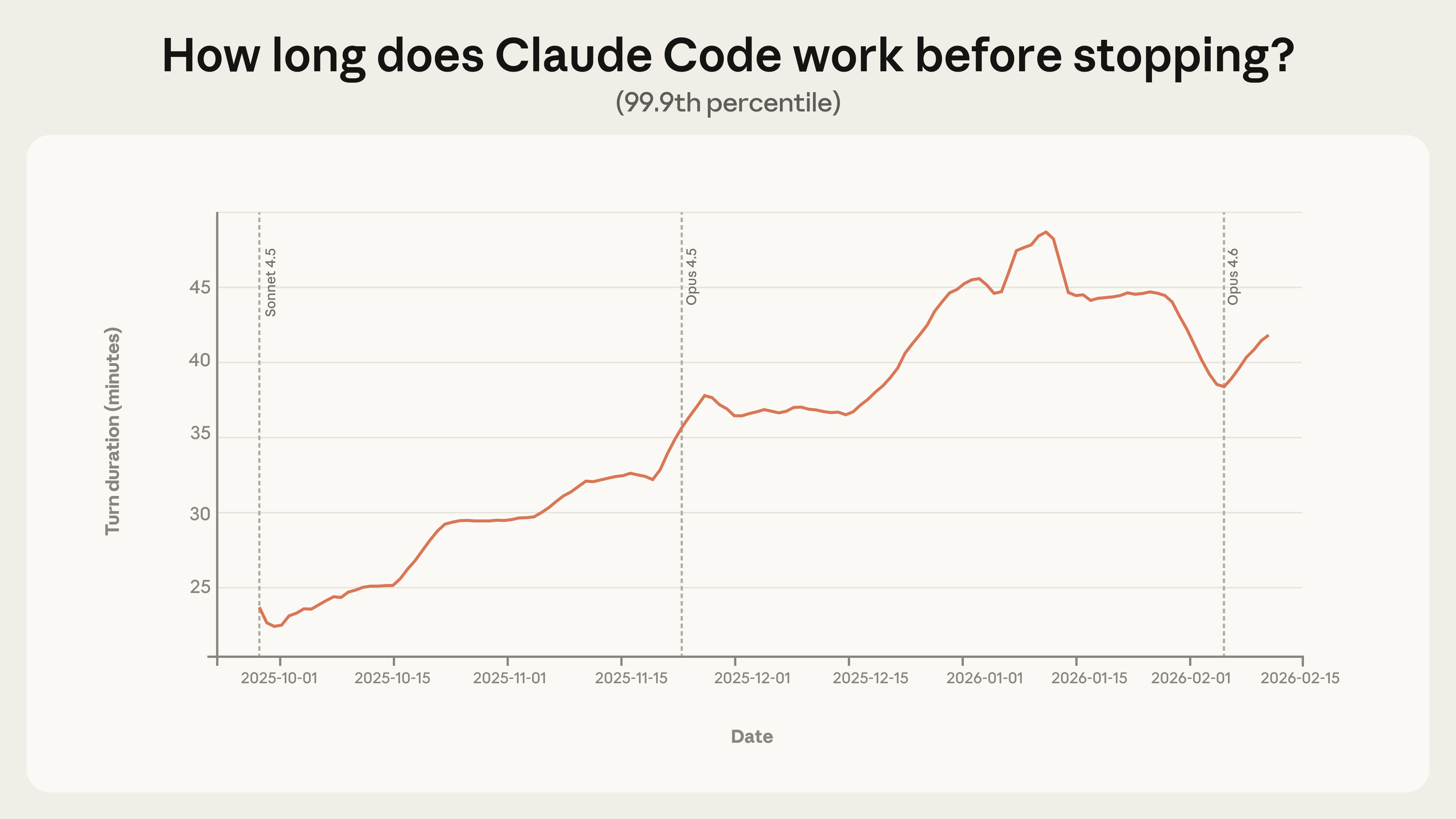 Image: AnthropicFigure 1. 99.9th percentile turn duration (how long Claude works on a per-turn basis) in interactive Claude Code sessions, 7-day rolling average. The 99.9th percentile has grown steadily from under 25 minutes in late September to over 45 minutes in early January. This analysis reflects all interactive Claude Code usage. (Anthropic) Source Full size
Image: AnthropicFigure 1. 99.9th percentile turn duration (how long Claude works on a per-turn basis) in interactive Claude Code sessions, 7-day rolling average. The 99.9th percentile has grown steadily from under 25 minutes in late September to over 45 minutes in early January. This analysis reflects all interactive Claude Code usage. (Anthropic) Source Full size
Long‑running sessions have nearly doubled in length – The 99.9th‑percentile turn duration grew from under 25 minutes in late September 2025 to over 45 minutes by early January 2026, a smooth trend across model releases suggesting factors beyond raw capability are at play [1].
Experienced users grant more autonomy but also intervene more – Auto‑approve usage climbs from roughly 20 % of sessions for newcomers to over 40 % after 750 sessions, while per‑turn interrupt rates rise from about 5 % to 9 % as users become seasoned [1].
Claude Code asks for clarification twice as often as humans interrupt on complex tasks – On the most demanding goals, the model’s self‑initiated pauses exceed human‑initiated interruptions by a factor of two, indicating built‑in uncertainty handling [1].
Agents operate mainly in low‑risk software engineering, with limited high‑risk use – Nearly 50 % of public‑API tool calls involve software engineering; 80 % include safeguards, 73 % retain a human in the loop, and only 0.8 % are irreversible, while emerging activity appears in healthcare, finance and cybersecurity [1].
Internal Claude Code usage shows higher success with fewer human interventions – From August to December, success on the hardest internal tasks doubled and average human interventions fell from 5.4 to 3.3 per session, reflecting growing trust and efficiency [1].
Study limited to Anthropic data and cannot reconstruct full agent sessions on the public API – The analysis covers only Anthropic‑hosted agents, treats API calls in isolation, and lacks visibility into downstream human review or multi‑step workflows, constraining generalizability [1].
Links
- [1] https://www.anthropic.com/research/measuring-agent-autonomy
- [10] https://www.anthropic.com/research/clio
- [11] https://github.com/anthropics/claude-code/blob/main/CHANGELOG.md
- [12] https://www.anthropic.com/news/anthropic-raises-30-billion-series-g-funding-380-billion-post-money-valuation
- [13] https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
- [14] https://red.anthropic.com/2026/zero-days/
- [15] https://www.anthropic.com/engineering/building-c-compiler
- [16] https://www.anthropic.com/news/our-framework-for-developing-safe-and-trustworthy-agents
- [17] https://code.claude.com/docs/en/common-workflows#use-plan-mode-for-safe-code-analysis
- [18] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [19] https://support.claude.com/en/articles/13345190-getting-started-with-cowork
- [2] https://www.anthropic.com/news/disrupting-AI-espionage
- [20] https://github.com/anthropics/claude-code/issues/535
- [21] https://code.claude.com/docs/en/monitoring-usage
- [22] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [23] https://dl.acm.org/doi/book/10.5555/773294
- [24] https://simonwillison.net/2025/Sep/18/agents/
- [25] https://arxiv.org/pdf/2504.21848
- [26] https://arxiv.org/abs/2311.02462
- [27] https://arxiv.org/abs/2506.12469
- [28] https://openai.com/index/practices-for-governing-agentic-ai-systems/
- [29] https://arxiv.org/abs/2502.02649
- [3] https://www.anthropic.com/research/clio
- [30] https://arxiv.org/pdf/2302.10329
- [31] https://arxiv.org/pdf/2401.13138
- [32] https://arxiv.org/abs/2407.01502
- [33] https://arxiv.org/abs/2512.04123
- [34] https://arxiv.org/abs/2512.07828
- [35] https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5713646
- [36] https://www.anthropic.com/research/how-ai-is-transforming-work-at-anthropic
- [37] https://www.anthropic.com/research/anthropic-interviewer
- [38] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [39] https://code.claude.com/docs/en/fast-mode
- [4] https://anthropic.com/research/measuring-agent-autonomy#claude-code-is-working-autonomously-for-longer
- [40] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [41] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [42] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [43] https://cdn.sanity.io/files/4zrzovbb/website/55e4d2de6eb39b3a9259c3f74843f86b1a12e265.pdf
- [5] https://www.anthropic.com/research/measuring-agent-autonomy#experienced-users-in-claude-code-auto-approve-more-frequently-but-interrupt-more-often
- [6] https://www.anthropic.com/research/measuring-agent-autonomy#claude-code-pauses-for-clarification-more-often-than-humans-interrupt-it
- [7] https://anthropic.com/research/measuring-agent-autonomy#agents-are-used-in-risky-domains-but-not-yet-at-scale
- [8] https://platform.claude.com/docs/en/api/overview
- [9] https://code.claude.com/docs/en/overview